

Los Superpoderes de la DATA: #5 CLASIFICACIÓN
Ya ha comenzado la cuenta atrás para la desaparición de las cookies de terceros en el navegador Chrome. Para llenar este vacío, que afecta tanto a la medición publicitaria como a las estrategias de segmentación, las marcas tienen por delante el reto de ser más imaginativas que nunca para poder explotar el potencial latente de sus datos propios. Y, para convertir esta materia prima en un producto refinado de alto valor, podrán apoyarse en el aprendizaje supervisado. Hablamos de una rama del Machine Learning que añade una capa de inteligencia a los datos y que, gracias a su capacidad de encontrar patrones de comportamiento, posee el superpoder de predecir el futuro…
Esta técnica de aprendizaje permite a los modelos aprender por sí mismos, siempre y cuando los entrenemos previamente a partir de ejemplos (de ahí el adjetivo de supervisado). Imaginad que queremos que el modelo identifique al personaje Spiderman en una foto. Para conseguirlo, tendremos que enseñarle varias fotos de superhéroes etiquetadas con su nombre correspondiente: Batman, Wonder Woman o Spiderman. Una vez consigamos adiestrar al modelo con miles de imágenes, será capaz de determinar si la foto contiene o no a Spiderman.

Dentro del campo del aprendizaje supervisado, existen 2 métodos: la regresión, que pronostica un valor numérico, y la clasificación, que deduce una categoría. En esta ocasión profundizaremos en este último concepto, y ya abordaremos la regresión en el próximo artículo.

¿Qué nos puede aportar todo esto en el entorno publicitario? Suponed que los superhéroes se convierten en usuarios y pretendemos predecir si realizarán compras en un futuro cercano. Si queremos averiguarlo, deberemos asignar nuestros usuarios a una categoría que distinga entre potenciales y no potenciales compradores.
Para poder vaticinar el resultado, lo primero que tenemos que hacer es analizar a los compradores actuales para poder determinar cuáles son las características propias que los diferencian del resto de la población. Para ello, utilizaremos un árbol de decisión que divida a los potenciales compradores del resto de los usuarios de la forma más homogénea posible en función de la información conocida sobre ellos. Como apunte, deciros que este árbol recibe el nombre por su semejanza con un árbol invertido cuando lo representamos gráficamente.
¿Cómo funciona? Distribuye al usuario en la rama izquierda o derecha en función de si cumple o no la propiedad deseada. En su raíz se produce la primera división en base a la característica más importante, mientras que los nodos finales del árbol indican dónde se encuentran la mayor proporción de convertidores. De esta forma, el modelo elabora un patrón de comportamiento de los convertidores que le permita después poder buscar perfiles similares. Igual os suena más si os digo que este modelo también es conocido por el nombre de lookalike.
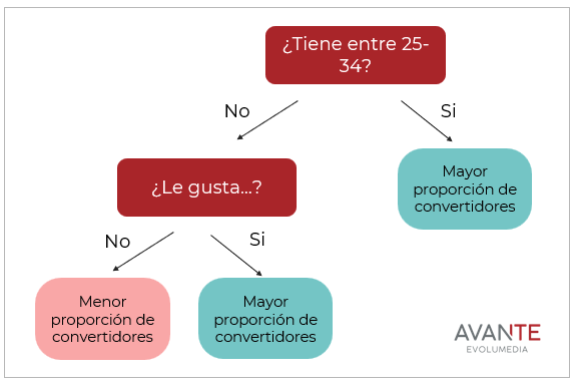
Los modelos de clasificación son herramientas muy potentes para llegar de manera efectiva a los consumidores potenciales de una marca. Con el histórico de los datos, podremos establecer el perfil de nuestros clientes y detectar a sus gemelos en nuevos usuarios.
En la siguiente entrega os contaré el siguiente paso: cómo adivinar las cifras…
Por Sophie Algarte, DATA Director de Avante Evolumedia